Businesses face a constant threat of unexpected disruptions. Whether it’s a natural disaster, cyberattack, or simple power outage, these events can bring operations to a standstill. Depending on the length and severity of the outage, businesses can lose revenue and erode customer trust. Having an up to date disaster recovery (DR) plan, and testing it frequently can help mitigate these risks and protect against data loss, and extended downtime. A key part of any DR plan is outlining the processes for failover and failback – operations that keep your business running during disruptions and enable a smooth transition back to your normal environment once the crisis is over.
What Is Failover?
Failover is the process of switching your critical applications and data to a temporary backup environment when your production environment encounters an outage. Unlike traditional disaster recovery solutions that rely on expensive standby hot sites, cloud backup recovery solutions like Cloud IBR automate failover by recovering Veeam backups stored offsite in object storage solutions such as Backblaze B2, Wasabi, or Cloudian. This eliminates the need to maintain costly duplicate repositories.
How Does Failover Work?
Failover relies on having backups of your critical data readily available. These backups are created using a backup and recovery software like Veeam, and can be stored securely on prem, offsite in object storage or in a private cloud.
When your primary system fails your backup environment is deployed to a bare metal cloud server. This becomes your temporary environment and allows operations to continue while you work on failing back to your production environment.
What Is Failback?
Failback is the process of transitioning operations back to your production environment.
How Does Failback Work?
Once the production environment has been restored, and any threats have subsided, the failback process can begin. While it mirrors the failover process in reverse, failback includes an essential step: synchronizing any changes made in the temporary recovery environment with the restored production system. Once synchronized, operations are moved seamlessly from the temporary environment back to production. The temporary environment is then backed up and prepared to serve as the recovery site for future events, or until it is replaced by a newer backup.
Failover Testing: Why It Matters
Failover testing is the process of simulating system failures to validate the transition to backup systems. It ensures that critical processes can continue seamlessly during disruptions and provides confidence in the failover mechanism’s ability to handle real-world scenarios.
Similar to disaster recovery testing, failover tests can unearth issues and provide time to fix before a disaster.
Key Benefits:
- Identify Vulnerabilities: Uncover gaps in the failover process before they impact operations.
- Enhance Reliability: Validate that redundancy mechanisms function as expected under stress.
- Ensure Scalability: Confirm that backup systems can handle demand during high-traffic periods.
Failover Testing vs. Disaster Recovery Testing:
Though failover and DR testing are often confused, they serve distinct purposes.
Failover testing focuses solely on validating the system’s ability to switch to backup environments during disruptions. In contrast, DR testing evaluates the entire recovery process, encompassing backups, personnel readiness, and long-term continuity planning.
While a failover test alone cannot replace a full DR test, a comprehensive DR test should always include failover testing as a critical component.
Cloud IBR’s Role in Simplifying Failover and Failback
Cloud IBR transforms disaster recovery by automating failover processes, offering businesses a cost-effective and efficient solution while allowing for tailored failback options.
Key Features:
- On-Demand Infrastructure: Deploys bare metal cloud servers only when needed, reducing costs.
- Automated Recovery: Recovers Veeam backups from object storage (Backblaze B2, Wasabi, Cloudian) or VCSP repositories.
- Access During DR Events: Enables access to offsite backups for immediate recovery.
- Platinum Plus Failback Services: Provides managed failback with options for automation and flexibility.
Technical Workflow
- One-Click Deployment: Bare metal cloud servers are deployed in seconds during a failover event.
- Backup Import: Automatically imports Veeam backups stored in object storage or managed by a VCSP.
- Immediate Failover: Provides a fully functional temporary environment with uninterrupted performance.
- Managed Failback (Platinum Plus): Synchronizes changes and transitions operations back to the production environment.
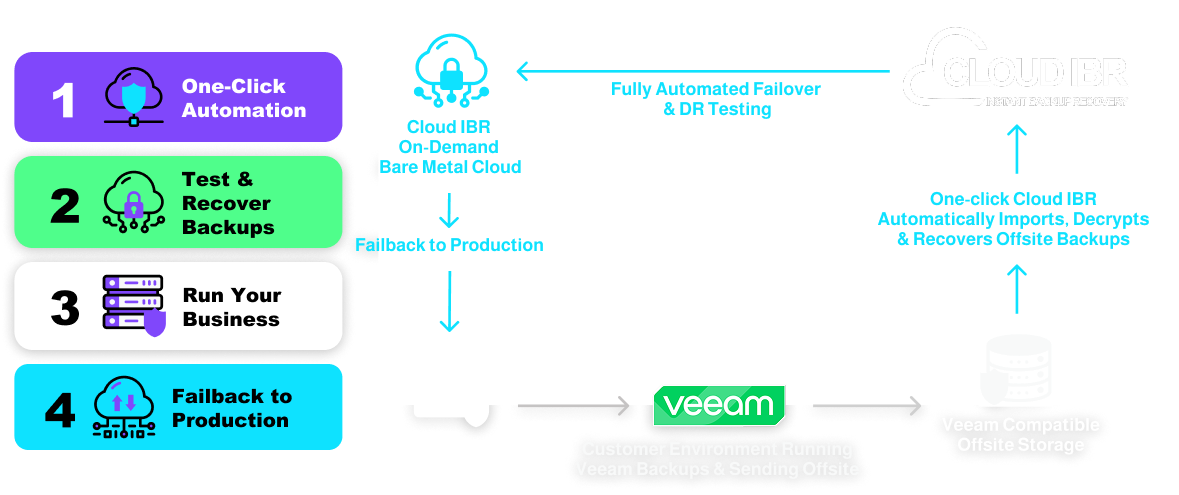
The diagram above illustrates how Cloud IBR works:
- Failover: Deploys bare metal cloud infrastructure on demand and runs backups from object storage (e.g., Wasabi, Backblaze B2, Cloudian) or VCSP repositories.
- Failback: Synchronizes changes and transitions operations back to the production environment with options for self-managed, MSP-assisted, or Platinum Plus services.
Why Choose Cloud IBR for Failover & Failback?
Efficiency: Reduce downtime with automated failover and customizable failback options.
Scalability: Handle growing workloads seamlessly during recovery.
Affordability: Pay-per-use model minimizes upfront investment.
Flexibility: Tailored failback options to fit your team’s expertise and budget.
Book a demo today to experience fast, flexible, and fully automated recovery that safeguards your business.

What Are Bare Metal Cloud Servers: A Guide to Bare Metal Recovery
Businesses need high-performance computing, stronger security and flexible infrastructure. While conventional cloud services offer scalability they often lack the raw power and control necessary for the demanding workloads of mission-critical

Backup vs Disaster Recovery: The Key Differences & Why You Need Both
Many organizations make a common mistake of confusing backups with disaster recovery (DR). Although they share the common goal of data protection, they serve distinct purposes. Regardless of how much

Lower Cyber-Insurance Premiums with One-Click DR Testing
Why Insurers Keep Raising the Bar Cyber‑insurance premiums more than doubled in key markets as ransomware surged, and businesses grew more reliant on digital infrastructure during the shift to remote